Introduction
In the rapidly evolving landscape of cloud computing, system resilience has emerged as a cornerstone for ensuring uninterrupted service delivery, especially as businesses increasingly depend on digital infrastructure. The resilience lifecycle framework, developed by Amazon Web Services (AWS), provides a systematic, iterative approach to enhancing the ability of applications and systems to withstand and recover from disruptions.
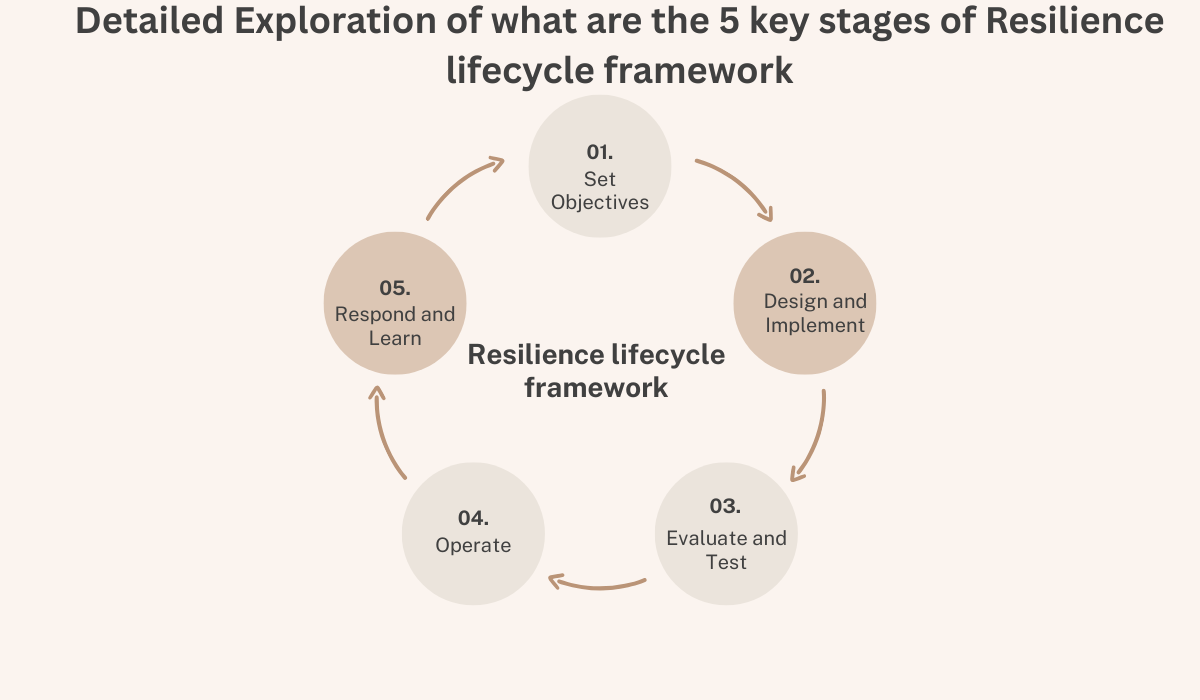
This blog explore that what are the 5 key stages of resilience lifecycle framework—Set Objectives, Design and Implement, Evaluate and Test, Operate, and Respond and Learn—offering detailed explanations, real-world examples, and insights into its application, particularly for a technology-focused audience like readers of mistyinfo.blog.
Background and Context
Resilience, in the context of cloud computing, refers to an application’s capacity to resist or recover from disruptions, including infrastructure failures, dependent service issues, misconfigurations, and transient network problems. As customer expectations shift toward an “always on, always available” mindset, with remote teams and complex, distributed applications, the need for resilience has never been greater. The AWS resilience lifecycle framework, introduced in October 2023, captures years of learnings and best practices, offering a continuous improvement model similar to software development lifecycles (SDLC). It applies at various levels, from individual components (e.g., code, servers, data stores) to entire systems, and is detailed in AWS documentation such as the prescriptive guidance available at AWS Resilience Lifecycle Framework.
The Five Key Stages: Detailed Breakdown
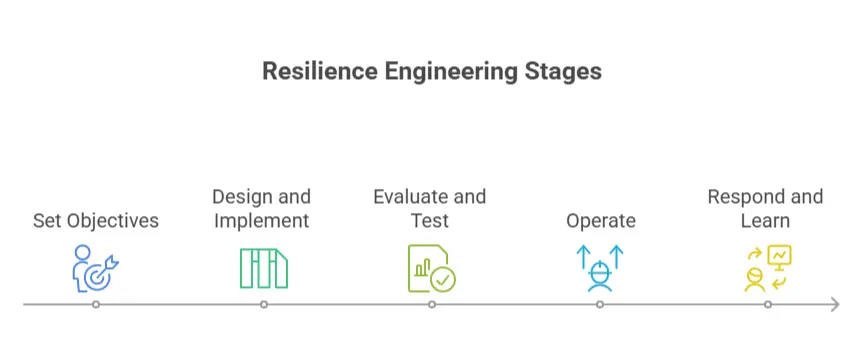
Stage 1: Set Objectives
The initial stage involves defining what resilience means for a specific application or system, aligning it with business needs. This includes mapping critical applications, understanding user stories, and setting measurable objectives such as Recovery Point Objectives (RPOs), Recovery Time Objectives (RTOs), and Service Level Objectives (SLOs). The process ensures that organizations can prioritize resources effectively, making informed trade-offs. For example, not all applications require the same level of resilience; a car analogy from AWS illustrates this: a car has four tires but carries only one spare, balancing resilience with other features like cargo space.
Example: Netflix, serving over 200 million subscribers globally, might set an objective of 99.99% uptime with an RTO of a few minutes. This stage is crucial for laying the foundation, ensuring subsequent efforts are goal-oriented.
Stage 2: Design and Implement
With objectives defined, this stage focuses on anticipating failure modes and designing systems to mitigate them. It involves leveraging best practices from the AWS Well-Architected Framework, understanding dependencies, planning disaster recovery strategies, and implementing continuous integration and continuous deployment (CI/CD) pipelines. Key activities include conducting Operational Readiness Reviews (ORRs), understanding AWS fault isolation boundaries, and modeling resilience, all while considering trade-offs like cost and complexity.
Example: Airbnb, a leader in travel and hospitality, uses AWS for automatic resource scaling and disaster recovery, employing multi-AZ deployments and auto-scaling groups. Their design ensures availability during regional outages, balancing resilience with operational efficiency.
Stage 3: Evaluate and Test
This stage ensures the system meets its resilience objectives through pre- and post-deployment testing. Activities include environment design, integration testing, automated deployment pipelines, load testing, and chaos engineering. Tools like AWS Resilience Hub and AWS Fault Injection Service (FIS) are pivotal, enabling organizations to simulate failures and assess recovery capabilities. Regular disaster recovery testing, such as failover and failback between regions, aligns with Reliability Pillar best practices from the AWS Well-Architected Framework.
Example: A case study from the AWS Cloud Operations Blog demonstrates this stage with a sample 3-tier application evaluated using AWS Resilience Hub. Initially failing RTO/RPO goals (RPO: 1 hour, RTO: 4 hours), it was improved via recommendations, achieving a “Policy met” status, as detailed at AWS Cloud Operations Blog. This highlights the importance of testing for identifying and addressing gaps.
| Activity | Description |
|---|---|
| Pre-deployment Testing | Environment design, integration testing, automated pipelines, load testing |
| Post-deployment Testing | Resilience assessments, DR testing, drift detection, synthetic testing, chaos engineering |
Stage 4: Operate
Once in production, the focus shifts to maintaining resilience through observability, event management, and continuous improvement. This includes implementing monitoring with tools like Amazon CloudWatch, setting up alerts via Amazon Simple Notification Service (SNS), and conducting regular reviews like AWS Well-Architected Framework assessments and game days. A culture of operational excellence ensures consistency in practices, with diverse perspectives (server-side and client-side monitoring) enhancing understanding of customer experience.
Example: Spotify, using a hybrid cloud with Google Cloud, implements robust monitoring and conducts game days to simulate incidents. This proactive approach ensures they stay ahead of potential disruptions, maintaining high availability for millions of users.
Stage 5: Respond and Learn
The final stage emphasizes learning from incidents to improve future resilience. When disruptions occur, the priority is to prevent further harm, followed by analyzing the incident through reports, operational reviews, and alarm performance evaluations (precision, false positives, false negatives, duplicative alerts). Training and enablement ensure teams are prepared, while creating an incident knowledge base and implementing resilience in depth foster a culture of continuous learning.
Example: Vanguard, a global investment firm, adopted the framework to build resilient applications on AWS, creating a Technology Resiliency Organization and analyzing past incidents to shift from reactive to proactive management, as discussed in an AWS video at AWS Resilience Lifecycle Implementation Guide. This demonstrates how learning from experiences enhances system reliability.
Real-World Applications and Case Studies
While the framework is AWS-centric, its principles are evident in broader cloud computing case studies. For instance:
- Dropbox: Uses Google Cloud for scalable storage and disaster recovery, ensuring high availability and faster sync times.
- NASA: Leverages AWS for large-scale data processing, reducing processing time and cost while maintaining high availability, aligning with resilience objectives.
- GE: Utilizes Microsoft Azure for real-time monitoring and disaster recovery, reducing downtime in manufacturing, as seen in the same source.
These examples, while not explicitly following the AWS framework, demonstrate its principles in action, showing how organizations build resilient systems through structured approaches.
Comparative Insights and Broader Context
The resilience lifecycle framework shares similarities with other lifecycle models, such as DevOps and ITIL, emphasizing continuous improvement and iterative processes. It fits into the broader context of cloud computing best practices, particularly the Reliability and Operational Excellence Pillars of the AWS Well-Architected Framework, available at AWS Well-Architected Framework. By integrating resilience into every stage, it addresses the dynamic, non-linear nature of modern systems, offering a holistic approach to managing disruptions.
Benefits and Challenges
Adopting the framework can reduce downtime, enhance customer satisfaction, and lower costs by optimizing resource allocation. However, challenges include balancing cost with complexity, requiring significant expertise and resources, especially for small and medium enterprises (SMEs). Public discussions, such as LinkedIn posts by professionals like Thiago Rodrigues at Thiago Rodrigues LinkedIn Post, highlight its adoption, though specific user experiences on platforms like Reddit were limited, suggesting a need for more community engagement.
In the end
The resilience lifecycle framework provides a comprehensive, structured approach to building and maintaining resilient systems in the cloud. By setting clear objectives, designing with resilience in mind, thoroughly testing, operating with observability, and learning from experiences, organizations can ensure their applications withstand modern computing challenges. Whether for startups or enterprises, this framework offers a roadmap to success, fostering reliability and competitiveness in a digital-first world.